CONTENT
The report is organized in the following sections:
In this report I briefly illustrate the exploratory analysis performed on a three datasets, comprising text from blogs, news and tweets.
The ultimate goal is to produce a light application able to predict text (words) given some preceding text, mimicking the predictive typing feature of modern software keyboard of portable devices.
As a playground a fairly substantial dataset was made available, comprising text from various heterogenous sources (blogs, news, twitter). These datasets are the foundation for developing an understanding of language processing and in turn devise a strategy for achieving the goal, and perhaps more importantly (in practice) they constitute our training and testing datasets.
I decided to invest a significant amount of time to explore the data, and delved (too) deeply into data cleaning, assuming that this effort will pay off by making any algorithm more robust.
At this stage in the project I will mostly review my exploratory analysis of the data, and outline my current thought about the strategy for developing the algorithm for the text-predicting application.
Performance issues: it is worth mentioning that one of the main challenges has been dealing smartly with the computational load, that turned out to be a serious limiting factor, even on a powerful workstation.
I did not use the suggested tm suite and relied instead heavily on perl and in R mainly dplyr, NLP and RWeka.
My current thoughts, very much in flux, about the strategy are that a n-grams based approach would be the most effective.
In particular, I am leaning towards a weighted combination of 2- 3- 4- 5-grams (linear interpolation), perhaps assisted by some additional information drawn from an analysis of the association of words in sentences or their distance within it.
An important issue that I have not yet had a chance to ponder sufficiently include the handling of “zeros”, i.e. words not included in the dictionary of the training set or, more importantly with a n-grams approach words that are not seen following a given (n-1) gram. In practice, based on my readings, this problem is tackled with some form of smoothing, that is assigning a probability to the “zeros” (and in turn re-allocating some mass probability away from the observed n-grams).
I have not yet had a chance to explore the feasibility and effectiveness of methods like Good-Turing or Stupid Backoff.
The report is organized in the following sections:
Libraries needed for data processing and plotting:
#-----------------------------
# NLP
library("tm")
library("SnowballC")
library("openNLP")
library("NLP")
# To help java fail less :-(
options( java.parameters = "-Xmx6g")
library("RWeka") # [NGramTokenizer], [Weka_control]
#-----------------------------
# general
library("dplyr")
library("magrittr")
library("devtools")
library("ggplot2")
library("gridExtra")
# library("RColorBrewer")
library("pander")
#-----------------------------
# my functions
source("./scripts/my_functions.R")
#-----------------------------The datasets are read-in separately into character vectors, using a user-defined compact function (readByLine()) (see Appendix for the short source).
# NOT EVALUATED because too computationally heavy (loading saved products)
in.blogs.ORIG <- readByLine("./data/en_US.blogs.ORIGINAL.txt.gz", check_nl = FALSE, skipNul = TRUE)
in.news.ORIG <- readByLine("./data/en_US.news.ORIGINAL.txt.gz", check_nl = FALSE, skipNul = TRUE)
in.twitter.ORIG <- readByLine("./data/en_US.twitter.ORIGINAL.txt.gz", check_nl = FALSE, skipNul = TRUE)Basic statistics of the three datasets in their original form:
# NOT EVALUATED
stats.blogs <- as.numeric(system("gzip -dc ./data/en_US.blogs.ORIGINAL.txt.gz | wc | awk '{print $1; print $2; print $3}'", intern = TRUE))
stats.news <- as.numeric(system("gzip -dc ./data/en_US.news.ORIGINAL.txt.gz | wc | awk '{print $1; print $2; print $3}'", intern = TRUE))
stats.twitter <- as.numeric(system("gzip -dc ./data/en_US.twitter.ORIGINAL.txt.gz | wc | awk '{print $1; print $2; print $3}'", intern = TRUE))
stats.ORIG.df <- data.frame( blogs = stats.blogs, news = stats.news, twitter = stats.twitter,
row.names = c("lines", "words", "characters"), stringsAsFactors = FALSE)
saveRDS(stats.ORIG.df, "data/stats_ORIGINAL.RDS")| blogs | news | ||
|---|---|---|---|
| lines | 899288 | 1010242 | 2360148 |
| words | 37334114 | 34365936 | 30359804 |
| characters | 210160014 | 205811889 | 167105338 |
After a quick review of the data with various R functions and packages, I decided to perform some cleaning of the text with standard Linux command line tools, mostly perl scripts. Broadly speaking I performed three categories of transformations:
which I will describe below.
The first task was to analyze the mix of invidual characters present in the three datasets with the goal of doing some homogeneization and tidying up of non-alphanumeric characters, such as quotes that can come in different forms.
The used method is not elegant, but effective enough, relying on a simple perl command substituting a series of non-odd characters with spaces, thus leaving a stream of odd characters subsequently parsed and cleaned to produce a list of odd characters sorted by their count.
perl -pe 's|[\d\w\$\,\.\!\?\(\);:\/\\\-=&%#_\~<>]||g; s|\s||g; s|[\^@"\+\*\[\]]||g;' | \
perl -pe "s/\'//g;" | \
egrep -v '^$' | \
split_to_singles.awk | \
sort -k 1 | uniq -c | sort -k 1nr
# split_to_singles.awk is a short awk script not worth including here (it's on GitHub)The number of unique odd characters found in each dataset are 2159 for blogs, 310 for news, 2087 for twitter.
The following is the census of odd characters appearing more than 500 times in each of the datasets (the full sorted lists are available on the GitHub repo in the data directory).
blogs news twitter
----------- ---------- ------------------------
387317 [’] 102911 [’] 27440 [“] 726 [»]
109154 [”] 48115 [—] 26895 [”] 718 [«]
108769 [“] 47090 [“] 11419 [’] 715 [😔]
50176 [–] 43992 [”] 5746 [♥] 686 [😉]
41129 […] 8650 [–] 5241 […] 680 [😳]
23836 [‘] 6991 [ø] 3838 [|] 639 [{]
18757 [—] 6723 [] 2353 [❤] 617 [•]
3963 [é] 6544 [] 2314 [–] 593 [‘]
2668 [£] 6267 [] 1799 [—] 578 [�]
1301 [′] 4898 [‘] 1333 [😊] 561 [💜]
914 [´] 3641 [] 1211 [👍] 560 [😃]
755 [″] 3319 [é] 1149 [😂] 544 [😏]
643 [€] 3062 […] 977 [é] 506 [☀]
624 [ā] 2056 [] 963 [😁] 503 [😜]
605 [½] 1408 [] 955 [☺]
598 [á] 1152 [�] 926 [😒]
582 [ö] 971 [•] 802 [`]
555 [è] 837 [½] 758 [😍]
518 [°] 711 [`] 751 [😘]
537 [ñ] 741 [}]For this preliminary stage I decided to not worry about accented letters, and characters from non-latin alphabet (e.g. asian, emoticons), but I thought it would be helpful to standardize a small set of very frequent characters, whose “meaning” is substantially equivalent
| blogs | news | TOTAL | |||
|---|---|---|---|---|---|
| quotes | [‘] | 23836 | 4898 | 593 | 29327 |
| [’] | 387317 | 102911 | 11419 | 501647 | |
| [“] | 108769 | 47090 | 27440 | 183299 | |
| [”] | 109154 | 43992 | 26895 | 180041 | |
| [«] | 0 | 0 | 718 | 718 | |
| [»] | 0 | 0 | 726 | 726 | |
| dashes | [–] | 50176 | 8650 | 2314 | 61140 |
| [—] | 48115 | 18757 | 1799 | 68671 | |
| ellipsis | […] | 41129 | 5241 | 3062 | 49432 |
During my initial attempts it immediately emerged the problem of excessively short rows of text. In particular, because I decided to perform tokenization on individual sentences, not directly on individual rows, the tokenizer tripped and failed on empty “sentences” resulting from short rows.
I have then decided to set a cutoff to the minimum acceptable length of rows. After some empirical testing and row-length analysis with command line tools I have set a threshold at \(\ge6\) words.
The rest of the analysis presented here is based on the cleaned datasets resulting from the processing described in the previous sections.
# NOT EVALUATED because too computationally heavy (loading saved products)
in.blogs.REG <- readByLine("./data/blogs_REG.txt.gz", check_nl = FALSE, skipNul = TRUE)
in.news.REG <- readByLine("./data/news_REG.txt.gz", check_nl = FALSE, skipNul = TRUE)
in.twitter.REG <- readByLine("./data/twitter_REG.txt.gz", check_nl = FALSE, skipNul = TRUE)Basic statistics of the three datasets in their original form:
# NOT EVALUATED
stats.blogs <- as.numeric(system("gzip -dc ./data/blogs_REG.txt.gz | wc | awk '{print $1; print $2; print $3}'", intern = TRUE))
stats.news <- as.numeric(system("gzip -dc ./data/news_REG.txt.gz | wc | awk '{print $1; print $2; print $3}'", intern = TRUE))
stats.twitter <- as.numeric(system("gzip -dc ./data/twitter_REG.txt.gz | wc | awk '{print $1; print $2; print $3}'", intern = TRUE))
stats.REG.df <- data.frame( blogs = stats.blogs, news = stats.news, twitter = stats.twitter,
row.names = c("lines", "words", "characters"), stringsAsFactors = FALSE)
saveRDS(stats.REG.df, "data/stats_REG.RDS")After preprocessing we have the following stats:
| blogs | news | ||
|---|---|---|---|
| lines | 793096 | 957228 | 2072644 |
| words | 36606082 | 33908035 | 29072455 |
| characters | 207683984 | 206471971 | 162152503 |
There are some common, customary, operations performed on a text dataset before proceeding to analyze it.
Given that the goal is to predict words in a typing context I think that removing stopwords does not make much sense.
Working with a text without stopwords may be useful if one wanted to use in the prediction algorithm some information about words’ association in sentences, which may help improve meaningful discrimination between different next word possibilities “proposed” by an algorithm based on n-grams.
Because of the context, I also do not think that removing punctuation would be wise, nor make sense.
The next step is applying the additional following three transformations:
Done as follows (with big obligatory acknowledgement and thank you to Hadley Wickham and Stefan Bache for bringing us the pipe %>%!).
# NOT EVALUATED because too computationally heavy (loading saved products)
in.blogs.REG <- tolower(in.blogs.REG) %>% removeNumbers() %>% stripWhitespace()
in.news.REG <- tolower(in.news.REG) %>% removeNumbers() %>% stripWhitespace()
in.twitter.REG <- tolower(in.twitter.REG) %>% removeNumbers() %>% stripWhitespace()
# re-uppercases TAGS
in.blogs.REG <- gsub('<(emoticon|hashtag|dollaramount|period|hour|profanity|usa|percentage|date|money|ass|space|decade|ordinal|number|telephonenumber|timeinterval)>',
'<\\U\\1>', in.blogs.REG, ignore.case = TRUE, perl = TRUE)
in.news.REG <- gsub('<(emoticon|hashtag|dollaramount|period|hour|profanity|usa|percentage|date|money|ass|space|decade|ordinal|number|telephonenumber|timeinterval)>',
'<\\U\\1>', in.news.REG, ignore.case = TRUE, perl = TRUE)
in.twitter.REG <- gsub('<(emoticon|hashtag|dollaramount|period|hour|profanity|usa|percentage|date|money|ass|space|decade|ordinal|number|telephonenumber|timeinterval)>',
'<\\U\\1>', in.twitter.REG, ignore.case = TRUE, perl = TRUE)As noted, after some tests, I settled on an approach whereby n-grams tokenization is performed on separate individual sentences, instead of directly on individual rows as loaded from the dataset.
This is motivated by the fact that the tokenizer I have adopted because I found its performance to be more satisfactory, the NGramTokenizer() of the RWeka package, does not seem to interrupt its construction of n-grams at what are very likely sentence boundaries.
With next word prediction in mind, it makes a lot of sense to restrict n-grams to sequences of words within the boundaries of a sentence.
Therefore, after cleaning, transforming and filtering the data, the first real operation I perform is the annotation of sentences, for which I have been using the openNLP sentence annotator Maxent_Sent_Token_Annotator(), with its default settings, and the function annotate() from the NLP package.
sent_token_annotator <- Maxent_Sent_Token_Annotator()
sent_token_annotator
# An annotator inheriting from classes
# Simple_Sent_Token_Annotator Annotator
# with description
# Computes sentence annotations using the Apache OpenNLP Maxent sentence detector
# employing the default model for language 'en'.I want the data in the form of a vector with individual sentences, and so I opted for sapply() combined with a function wrapping the operations necessary to prepare a row of data for annotation, the annotation itself and finally return a vector of sentences.
find_sentences <- function(x) {
s <- paste(x, collapse = " ") %>% as.String()
a <- NLP::annotate(s , sent_token_annotator)
as.vector(s[a])
}To work around not fully performance issues, the tokenization was done on subsets (chunk) of the data, comprising \(100000\) lines. Done this way was much faster than forcing the tokenization over the The following code takes each dataset, and splits it into sentences chunk by chunk, writing out the sentences for each chunk to separate files, which were then concatenated outside of R.
# NOT EVALUATED because too computationally heavy (loading saved products)
chunk_size <- 100000
for( what in c("blogs", "news", "twitter")) {
data.what <- get(paste0("in.", what, ".REG"))
len.what <- length(data.what)
cat(" - length ", len.what, "\n")
n_chunks <- floor(len.what/chunk_size) + 1
n1 <- ((1:n_chunks)-1)*chunk_size + 1
n2 <- (1:n_chunks)*chunk_size
n2[n_chunks] <- len.what
Ns_by_chunk <- rep(0, n_chunks)
print(n1)
print(n2)
names <- paste(what, "sentences", sprintf("%02d", (1:n_chunks)), sep = ".")
fnames <- paste(names, ".gz", sep = "")
print(names)
print(fnames)
# loop over chunks of size 'chunk_size'
for(i in 1:n_chunks) {
name1 <- names[i]
fname1 <- fnames[i]
idx <- n1[i]:n2[i]
cat(" ", name1, length(idx), idx[1], idx[length(idx)], "\n")
# find sentences
assign( name1, sapply(data.what[idx], FUN = find_sentences, USE.NAMES = FALSE) %>% unlist )
con <- gzfile(fname1, open = "w")
# write sentences for this chunk to file
writeLines(get(name1), con = con)
close(con)
}
rm(i, n1, n2, n_chunks)
}The stats table, with the added number of sentences is now as follows:
| blogs | news | ||
|---|---|---|---|
| lines | 793096 | 957228 | 2072644 |
| words | 36606082 | 33908035 | 29072455 |
| characters | 207683984 | 206471971 | 162152503 |
| sentences | 2136323 | 1819982 | 3257495 |
| sentences_per_line | 2.694 | 1.901 | 1.572 |
The list of sentences by dataset were then merged into a single master list.
After the tokenization into sentences, some more fixes were applied with perl scripts (sources posted on GitHub
gzip -dc all.sentences.ALL.gz | \
./sentences_cleaning-v1.pl | \
awk '{if(NF > 1){print $0}}' | \
./sentences_cleaning-v2.pl | \
./sentences_cleaning-v2.pl | \
./sentences_cleaning-v2.pl | \
./sentences_cleaning-v3.pl | \
./sentences_cleaning-v2.plThe repetition of script #2 turned out to be an easier approach instead of writing more complex regular expressions.
The processed sentences were then filtered based on
NF in awk).
awk '{if(NF < 3){next}; ratio = (length - NF + 1)/NF; if(ratio > 7.0){next}; print $0}' After more thinking I decided to partially reconsider my decision against removal of stop words and remove a controlled, selected list of them.
my_stop_words <- c("a", "an", "as", "at", "no", "of", "on", "or",
"by", "so", "up", "or", "no", "in", "to", "rt")
# fixing extra spaces left by removing stop words
all.sentences <- removeWords(all.sentences.ALL, my_stop_words) %>%
gsub(" +", " ", . , perl = TRUE) %>%
gsub("^ +", "", . , perl = TRUE) %>%
gsub(" +$", "", . , perl = TRUE)For the n-grams tokenization I used the RWeka Tokenizer NGramTokenizer, passing to it a list of token delimiters.
I have not been able to run NGramTokenizer() on the full vector of sentences for each data set. It fails on some variation of memory-allocation related error (that honestly does not make much sense to me considering that I am running it on machines with 12GB of RAM).
So, I am processing data in chunks of 25,000 sentences, as exemplified by this block of code (the n-grams data for the following section are loaded from saved previous analysis).
I extracted n-grams for \(n = 3, 4, 5\), with the code shown below:
token_delim <- " \\r\\n\\t.,;:\"()?!"
nl.chunk <- 25000
gc()
cat(" *** Tokenizing n-grams in WHOLE dataset [", my_date(), "]----------------------------------------\n")
len.all.sentences <- length(all.sentences)
cat(" *** Number of sentences in the WHOLE data set : ", len.all.sentences, "\n")
# define variable used to filter sentences long enough for n-grams of length N
subs <- strsplit(all.sentences, split = "[ ;,.\"\t\r\n()!?]+")
nstr.subs <- sapply(subs, FUN = function(x) { length(unlist(x)) }, USE.NAMES = FALSE)
rm(subs)
for( ngram_size in 3:5 ) {
cat(" *** Tokenizing : WHOLE : ", ngram_size, "-grams ----------------------------------------\n")
good.sentences <- all.sentences[nstr.subs >= ngram_size]
len.good <- length(good.sentences)
cat(" Sentences with good length ( >=", ngram_size, ") : ", sprintf("%7d", len.good), "\n")
cat(" Sentences with good length ( >=", ngram_size, ") : ", sprintf("%7d", len.good),
"(of ", sprintf("%7d", len.all.sentences), ")\n")
n_chunks <- floor(len.good/nl.chunk) + 1
n1 <- ((1:n_chunks)-1)*nl.chunk + 1
n2 <- (1:n_chunks)*nl.chunk
n2[n_chunks] <- len.good
names <- paste("n", sprintf("%1d", ngram_size), "grams.blogs.", sprintf("%03d", (1:n_chunks)), sep = "")
fnames <- paste("output/", names, ".gz", sep = "")
for(i in 1:n_chunks) {
name1 <- names[i]
fname1 <- fnames[i]
idx <- n1[i]:n2[i]
cat(" [", sprintf("%3d", i), "/", sprintf("%3d", n_chunks), "] ",
name1, length(idx), idx[1], idx[length(idx)], "\n")
# tokenize to n-grams
assign( name1, NGramTokenizer(good.sentences[idx],
Weka_control(min = ngram_size, max = ngram_size, delimiters = token_delim)) )
# write to file n-grams from this chunk
con <- gzfile(fname1, open = "w")
writeLines(get(name1), con = con)
close(con)
gc()
}
# Combining chunks into one n-gram vector
size.ngrams <- rep(0, n_chunks)
total_length <- 0
for(i in 1:n_chunks) {
name1 <- names[i]
this_length <- length(get(name1))
size.ngrams[i] <- this_length
total_length <- total_length + this_length
cat(" [", sprintf("%3d", i), "/", sprintf("%3d", n_chunks),
"] length of ", name1, " = ", this_length, "\n")
}
cat(" Total Length = ", total_length, "\n")
name_for_all_ngrams <- paste("n", sprintf("%1d", ngram_size), "grams.blogs.all", sep = "")
temp_all_ngrams <- vector(mode = "character", length = total_length)
ivec <- c(0, cumsum(size.ngrams))
for(i in 1:n_chunks) {
i1 <- ivec[i] + 1
i2 <- ivec[i+1]
name <- names[i]
cat(" ", i, i1, i2, name, "\n")
temp_all_ngrams[i1:i2] <- get(name)
}
assign( name_for_all_ngrams, temp_all_ngrams )
# write to file all n-grams
fname <- paste("output/", "n", sprintf("%1d", ngram_size), "grams.blogs.all.gz", sep = "")
con <- gzfile(fname, open = "w")
writeLines(temp_all_ngrams, con = con)
close(con)
# cleaning
rm(good.sentences, len.good, temp_all_ngrams)
rm(i, n1, n2, n_chunks)
ls(pattern = "^n[1-6]grams.blogs.[0-9]")
rm(list = ls(pattern = "^n[1-6]grams.blogs.[0-9]") )
gc()
}A small fraction of the n-grams so produced contains no-ASCII characters, and it makes sense to simply drop these n-grams.
For instance with:
gzip -dc n5grams.all.gz | grep -P -v '([^\x00-\x7F]+)' Another perl script (ngrams-reprocess_clean_and_classify.pl, find it on GitHub) then
gzip -dc n5grams.filtered_for_nonASCII.gz | ./scripts/ngrams-reprocess_clean_and_classify.pl -go -printThis script produces a set of 7 files (tmp_n*) containing: * good 1-grams * good 2-grams * good 3-grams * good 4-grams * good 5-grams * n > 5 grams * Trashed n-grams (full of problem not worth dealing with)
Finally, we merge the n-grams of each order produced by the above script reprocessing all original n-grams.
NOTE: the following results refer to the analysis of a subset of sentences (20%).
From the n-grams vectors we can compute frequencies, which will be an important basis for the prediction algorithms.
For now we can take a peek at what are the most frequent 3-grams and 4-grams in the three datasets.
n3g.blogs.freq <- as.data.frame(table(n3grams.blogs.all), stringsAsFactors = FALSE)
n3g.blogs.freq <- n3g.blogs.freq[order(n3g.blogs.freq$Freq, decreasing = TRUE), ]
row.names(n3g.blogs.freq) <- NULL
n4g.blogs.freq <- as.data.frame(table(n4grams.blogs.all), stringsAsFactors = FALSE)
n4g.blogs.freq <- n4g.blogs.freq[order(n4g.blogs.freq$Freq, decreasing = TRUE), ]
row.names(n4g.blogs.freq) <- NULL
colnames(n3g.blogs.freq) <- c("ngram", "count")
colnames(n4g.blogs.freq) <- c("ngram", "count")n3g.news.freq <- as.data.frame(table(n3grams.news.all), stringsAsFactors = FALSE)
n3g.news.freq <- n3g.news.freq[order(n3g.news.freq$Freq, decreasing = TRUE), ]
row.names(n3g.news.freq) <- NULL
n4g.news.freq <- as.data.frame(table(n4grams.news.all), stringsAsFactors = FALSE)
n4g.news.freq <- n4g.news.freq[order(n4g.news.freq$Freq, decreasing = TRUE), ]
row.names(n4g.news.freq) <- NULL
colnames(n3g.news.freq) <- c("ngram", "count")
colnames(n4g.news.freq) <- c("ngram", "count")n3g.twitter.freq <- as.data.frame(table(n3grams.twitter.all), stringsAsFactors = FALSE)
n3g.twitter.freq <- n3g.twitter.freq[order(n3g.twitter.freq$Freq, decreasing = TRUE), ]
row.names(n3g.twitter.freq) <- NULL
n4g.twitter.freq <- as.data.frame(table(n4grams.twitter.all), stringsAsFactors = FALSE)
n4g.twitter.freq <- n4g.twitter.freq[order(n4g.twitter.freq$Freq, decreasing = TRUE), ]
row.names(n4g.twitter.freq) <- NULL
colnames(n3g.twitter.freq) <- c("ngram", "count")
colnames(n4g.twitter.freq) <- c("ngram", "count")tmp3.df <- cbind(head(n3g.blogs.top500, 20),
head(n3g.news.top500, 20),
head(n3g.twitter.top500, 20))
tmp4.df <- cbind(head(n4g.blogs.top500, 20),
head(n4g.news.top500, 20),
head(n4g.twitter.top500, 20))
colnames(tmp4.df) <- c("ngram_blogs", "count", "ngram_news", "count", "ngram_twitter", "count")
colnames(tmp4.df) <- c("ngram_blogs", "count", "ngram_news", "count", "ngram_twitter", "count")
# saveRDS(tmp3.df, file = "tmp_n3g_table.RDS")print(tmp3.df[, 1:2], print.gap = 3, right = FALSE)
# ngram count
# 1 one of the 4416
# 2 a lot of 3613
# 3 to be a 2078
# 4 it was a 2076
# 5 as well as 2067
# 6 some of the 1988
# 7 the end of 1974
# 8 out of the 1954
# 9 be able to 1927
# 10 i want to 1882
# 11 a couple of 1828
# 12 the fact that 1596
# 13 this is a 1592
# 14 the rest of 1539
# 15 going to be 1521
# 16 part of the 1478
# 17 i_am going to 1448
# 18 i do_not know 1425
# 19 one of my 1408
# 20 i had to 1373print(tmp3.df[, 3:4], print.gap = 3, right = FALSE)
# ngram count
# 1 the united states 1324
# 2 the first time 1249
# 3 for the first 1021
# 4 more than <DOLLARAMOUNT> 1000
# 5 the end the 896
# 6 it would be 751
# 7 it was the 722
# 8 the fact that 690
# 9 <DOLLARAMOUNT> - <DOLLARAMOUNT> 680
# 10 this is the 679
# 11 the rest the 676
# 12 said he was 667
# 13 he said he 655
# 14 i do_not think 652
# 15 the new york 651
# 16 he said the 628
# 17 i do_not know 626
# 18 for more than 622
# 19 the same time 578
# 20 when he was 565print(tmp3.df[, 5:6], print.gap = 3, right = FALSE)
# ngram count
# 1 thanks for the 7135
# 2 thank you for 2590
# 3 i love you 2474
# 4 for the follow 2334
# 5 for the rt 1311
# 6 let me know 1301
# 7 i do_not know 1265
# 8 i feel like 1179
# 9 i wish i 1154
# 10 thanks for following 1048
# 11 you for the 1013
# 12 i can_not wait 968
# 13 <HASHTAG> <HASHTAG> <HASHTAG> 963
# 14 how are you 960
# 15 for the <HASHTAG> 958
# 16 can_not wait for 919
# 17 rt : i 915
# 18 i think i 895
# 19 if you want 867
# 20 what do you 858print(tmp4.df[, 1:2], print.gap = 3, right = FALSE)
# ngram_blogs count
# 1 the end of the 1011
# 2 the rest of the 913
# 3 at the end of 872
# 4 at the same time 700
# 5 when it comes to 611
# 6 one of the most 610
# 7 to be able to 578
# 8 for the first time 565
# 9 in the middle of 519
# 10 if you want to 469
# 11 is one of the 462
# 12 i do_not want to 461
# 13 a bit of a 403
# 14 i was going to 395
# 15 on the other hand 393
# 16 i would like to 375
# 17 one of my favorite 350
# 18 as well as the 325
# 19 i was able to 304
# 20 is going to be 302print(tmp4.df[, 3:4], print.gap = 3, right = FALSE)
# ngram_news count
# 1 for the first time 791
# 2 more than <DOLLARAMOUNT> million 398
# 3 the first time since 195
# 4 more than <DOLLARAMOUNT> billion 150
# 5 for more than years 138
# 6 feet <DATE> for <DOLLARAMOUNT> 137
# 7 square feet <DATE> for 137
# 8 <DOLLARAMOUNT> million <DOLLARAMOUNT> million 136
# 9 for the most part 133
# 10 the past two years 132
# 11 told the associated press 132
# 12 the united states and 131
# 13 i do_not know if 126
# 14 the end the year 126
# 15 the end the day 124
# 16 g fat g saturated 118
# 17 the new york times 118
# 18 dow jones industrial average 114
# 19 be reached for comment 112
# 20 i do_not know what 112print(tmp4.df[, 5:6], print.gap = 3, right = FALSE)
# ngram_twitter count
# 1 thanks for the follow 1882
# 2 thanks for the rt 1031
# 3 thank you for the 916
# 4 for the first time 513
# 5 i wish i could 410
# 6 thanks for the <HASHTAG> 375
# 7 rt : rt : 358
# 8 thanks for the mention 358
# 9 let me know if 330
# 10 <HASHTAG> <HASHTAG> <HASHTAG> <HASHTAG> 322
# 11 that awkward moment when 299
# 12 what do you think 292
# 13 thank you much for 276
# 14 hope all is well 266
# 15 can_not wait for the 262
# 16 thanks for the shout 257
# 17 for the shout out 254
# 18 i thought it was 243
# 19 thank you for following 240
# 20 thank you for your 232It is apparent that there some work will be necessary on the validation of the n-grams, or better still further text transformations, in particular of the twitter data set that “suffers” from the tendency of using shorthand slang (e.g. “rt” for “re-tweet”) that adds a lot of “noise” to the data.
# ECHO FALSE
mycolors <- c("deepskyblue3", "firebrick2", "forestgreen")
data2pl <- n4g.high.sorted[1:30, ]
bp_mix <- ggplot(data2pl, aes(x = reorder(ngram, count), y = count)) + theme_bw() + coord_flip() + xlab("") +
theme(plot.title = element_text(face = "bold", size = 20)) +
theme(axis.text = element_text(size = 10)) +
scale_fill_manual(values = mycolors) +
ggtitle("Top 30 4-grams : all sources") +
geom_bar(stat = "identity", aes(fill = flag)) +
geom_text(aes(label = count, hjust = 1.1, size = 10), col = "white", position = position_stack())
bp_mix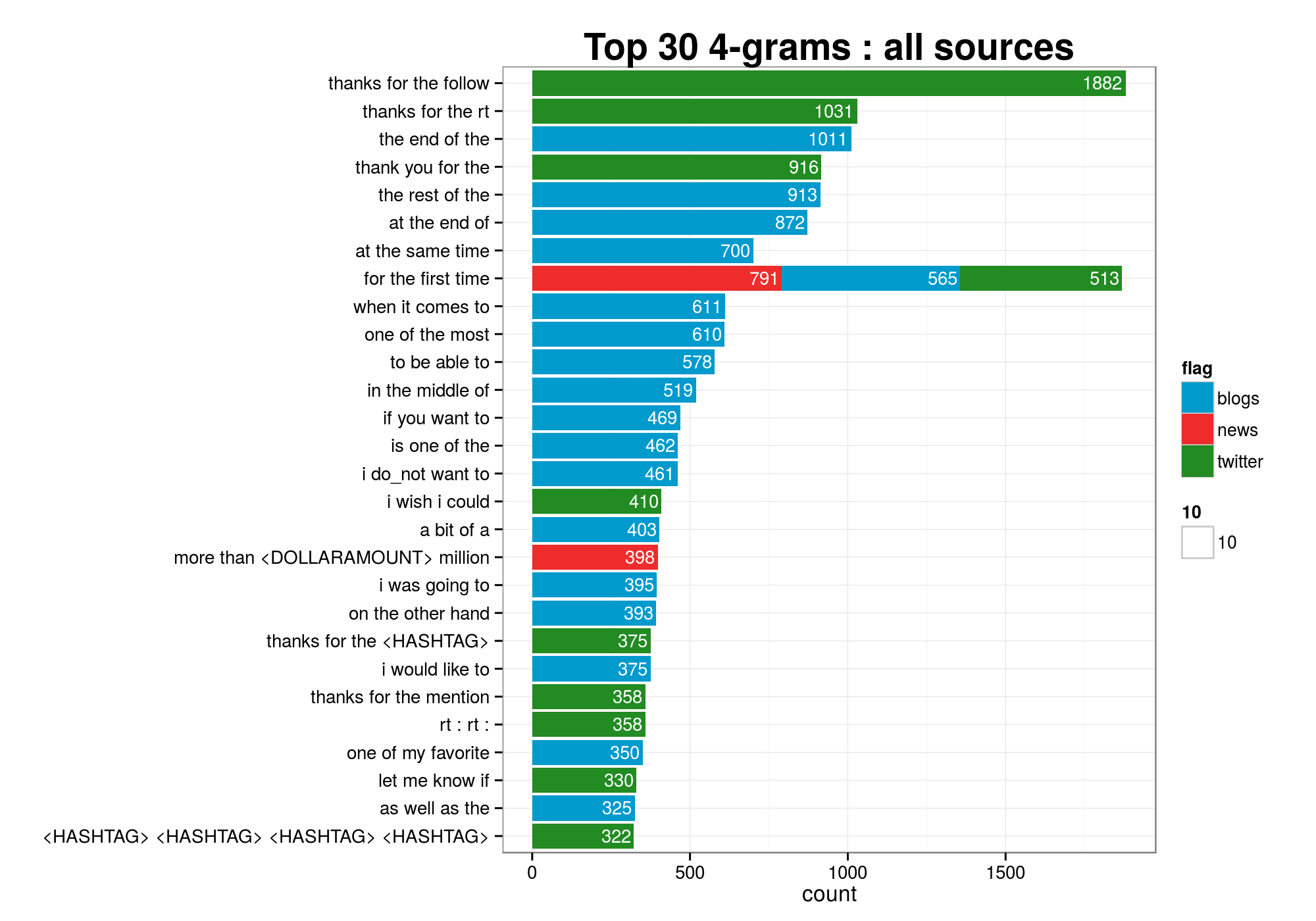
# ECHO FALSE
data.blogs <- n4g.blogs.top500[1:20, ]
bp_blogs <- ggplot(data.blogs, aes(x = reorder(ngram, count), y = count)) + theme_bw() + coord_flip() + xlab("") +
theme(plot.title = element_text(face = "bold", size = 20)) +
theme(axis.text = element_text(size = 10)) +
theme(legend.position = "none") +
ggtitle("Top 20 4-grams : blogs") +
geom_bar(stat = "identity", fill = mycolors[1]) +
geom_text(aes(label = count, y = 100, size = 10), col = "white")
data.news <- n4g.news.top500[1:20, ]
bp_news <- ggplot(data.news, aes(x = reorder(ngram, count), y = count)) + theme_bw() + coord_flip() + xlab("") +
theme(plot.title = element_text(face = "bold", size = 20)) +
theme(axis.text = element_text(size = 10)) +
theme(legend.position = "none") +
ggtitle("Top 20 4-grams : news") +
geom_bar(stat = "identity", fill = mycolors[2]) +
geom_text(aes(label = count, y = 100, size = 10), col = "white")
data.twitter <- n4g.twitter.top500[1:20, ]
bp_twitter <- ggplot(data.twitter, aes(x = reorder(ngram, count), y = count)) + theme_bw() + coord_flip() + xlab("") +
theme(plot.title = element_text(face = "bold", size = 20)) +
theme(axis.text = element_text(size = 10)) +
theme(legend.position = "none") +
ggtitle("Top 20 4-grams : twitter") +
geom_bar(stat = "identity", fill = mycolors[3]) +
geom_text(aes(label = count, y = 100, size = 10), col = "white")
grid.arrange(bp_blogs, bp_news, bp_twitter, nrow = 3)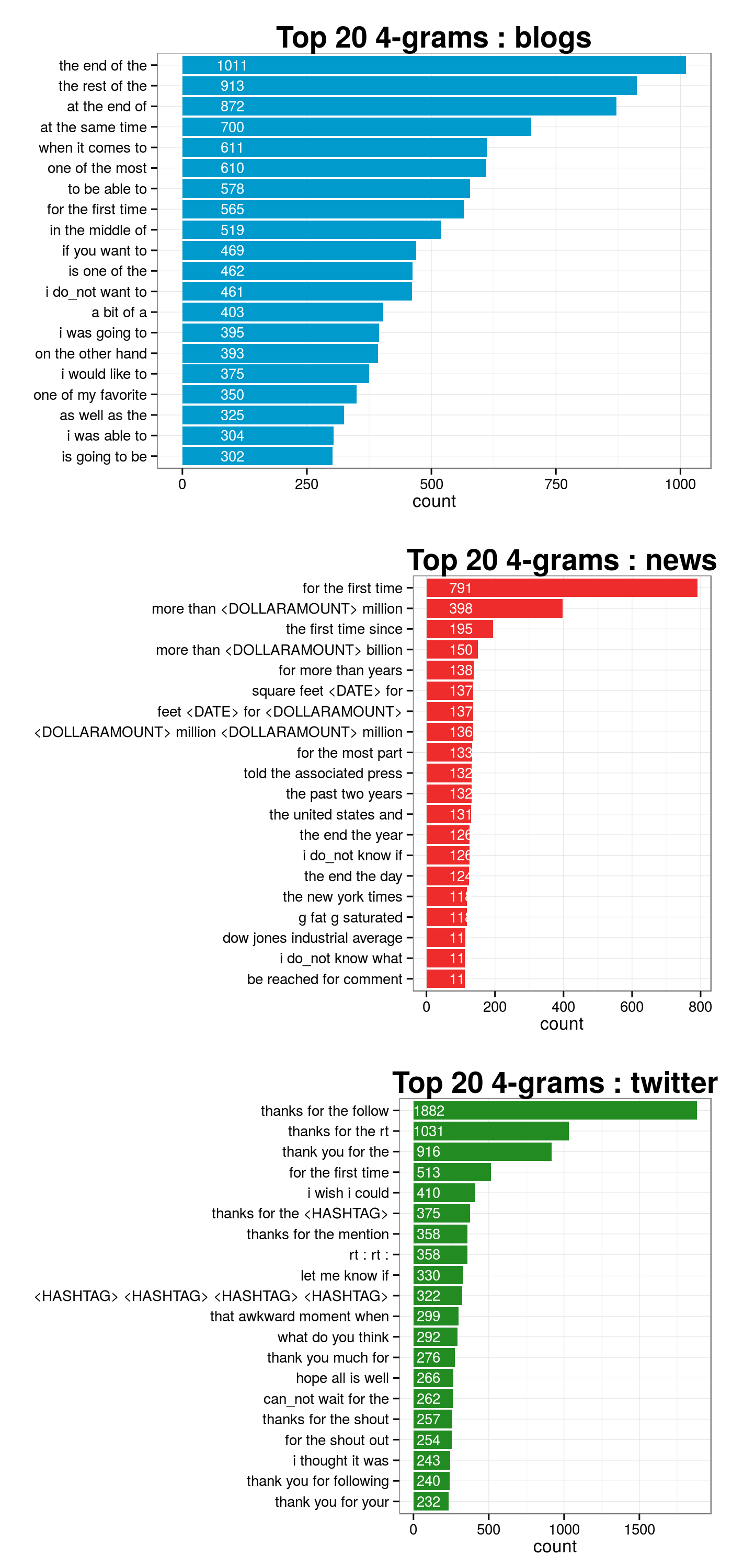
These are two handy functions used in the analysis.
sapply() to annotate sentences, allowing to work by row instead of converting the whole dataset into one document.#===================================================================================================
# modified readLines
readByLine <- function(fname, check_nl = TRUE, skipNul = TRUE) {
if( check_nl ) {
cmd.nl <- paste("gzip -dc", fname, "| wc -l | awk '{print $1}'", sep = " ")
nl <- system(cmd.nl, intern = TRUE)
} else {
nl <- -1L
}
con <- gzfile(fname, open = "r")
on.exit(close(con))
readLines(con, n = nl, skipNul = skipNul)
}
#===================================================================================================
# to use w/ sapply for finer sentence splitting.
find_sentences <- function(x) {
s <- paste(x, collapse = " ") %>% as.String()
a <- NLP::annotate(s , sent_token_annotator)
as.vector(s[a])
}
#===================================================================================================More functions can be reviewed directly from the repository
Scripts source in this GitHub folder
Scripts source in this GitHub folder
More catching of profanities
NGramTokenizerBecause the NGramTokenizer would fail with a java memory error if fed the full vector of sentences, but run when fed chunks of 100,000 sentences, I thought that turning this into a basic loop handling the splitting in chunks, collecting the output and finally return just one vector of n-grams would work, be compact and smarter.
It turns out that it fails… and this puzzles me deeply.
Is R somehow handling the “stuff” in the loop in the same way it would if I run the tokenizer with the full vector?
Any clue?
# NOT EVALUATED
nl.chunk <- 100000
N <- ceiling(length(sel.blogs.sentences)/nl.chunk)
alt.n3grams.blogs <- vector("list", N)
system.time({
for( i in 1:N ) {
i <- i+1
n1 <- (i-1)*nl.chunk + 1
n2 <- min(i*nl.chunk, end.blogs)
cat(" ", i, n1, n2, "\n")
alt.n3grams.blogs[[i]] <- NGramTokenizer(sel.blogs.sentences[n1:n2],
Weka_control(min = 3, max = 3,
delimiters = token_delim))
}
})